
.png&blockId=7628ec0c-1357-4c37-a1e9-32a282f6efaa)



.png&blockId=be06ed4d-0152-4f0f-b4b4-821bd1fb30d9)
.png&blockId=39a86e12-3cf4-40df-8d5e-9891c5adc274)


_%25E1%2584%2587%25E1%2585%25A9%25E1%2586%25A8%25E1%2584%2589%25E1%2585%25A1%25E1%2584%2587%25E1%2585%25A9%25E1%2586%25AB.png&blockId=891e6648-1148-4e7c-bfcd-0463dc71545c)

.png&blockId=5e737e69-4f36-437b-95e0-7db747173000)
.png&blockId=5294c22e-8cee-4109-963f-c8cfe8c852cf)
 경로 표현식
경로 표현식
경로표현식을 알면 JPQL이 어떻게 SQL로 변환되는 지 명확히 이해할 수 있다!!
•
.(점)을 찍어 객체 그래프를 탐색하는 것
select m.username // 상태 필드 from Member m
join m.team t // 단일 값 연관 필드
join m.orders o // 컬렉션 값 연관 필드
where t.name = '팀A'
SQL
복사
•
상태 필드(state field): 단순히 값을 저장하기 위한 필드 (ex: m.username)
•
연관 필드(association field): 연관관계를 위한 필드
◦
단일 값 연관 필드:
→ @ManyToOne, @OneToOne, 대상이 엔티티(ex: m.team)
◦
컬렉션 값 연관 필드:
→ @OneToMany, @ManyToMany, 대상이 컬렉션(ex: m.orders)
특징
•
상태필드 : 경로 탐색의 끝, 탐색X
em.createQuery("select m.username from Member m ")
Java
복사
◦
해당 쿼리를 보낼 경우 m.username 이외에 더 탐색하지 않는다.
◦
앞의 글에서 Member Class가 있는데, 이는 id, username, team으로 이루어져 있다고 보면 되는데, username은 String 타입으로 더 나아갈 곳이 존재하지 않는다
→ m.username.~~ 이 존재하지 않다는 의미
•
단일 값 연관 경로 : 묵시적 내부 조인(inner join) 발생, 탐색O ⇒ 굉장히 중요!!
em.createQuery("select m.team from Member m ")
em.createQuery("select m.team.id from Member m ")
em.createQuery("select m.team.name from Member m ")
Java
복사
◦
해당 쿼리를 보낼 경우 묵시적 조인이 발생하며 더 탐색할 수 있다.
→ 이는 JPQL 쿼리 상 join과 관련된 내용은 없지만, 실제로 쿼리가 나가게 된다면 join 쿼리가 실행된다는 의미
◦
m.team을 보면 team은 하나의 엔티티이기 때문에 team 안으로 들어가 더 조회할 수 있다.
→ m.team.name과 같이 team의 이름을 조회하는 것까지 가능하다는 의미
◦
여기서 m.team.name, m.team.id와 같이 더 나아가면 탐색의 끝이 되게 때문에, 상태 필드가 된다.
•
컬렉션 값 연관 경로 : 묵시적 내부 조인 발생, 탐색X
em.createQuery("select t.members from Team t ")
Java
복사
◦
해당 쿼리는 더 이상 탐색을 하지 못한다.
◦
만약 JPQL을 잘 모른다고 가정한다면, t.members.~ 가 가능하다고 생각할 수 있지만, 보통 컬렉션은 OneToMany 관계이기 때문이다.
→ 이는 반환 값이 Collection.Class이기 때문에 더 이상 탐색할 수 없다.
→ size는 가능!
◦
만약, t.members에서 꼭 가져와야겠다면 방법은 있다.
→ FROM 절에서 명시적 조인을 통해 별칭을 얻으면 별칭을 통해 탐색이 가능하긴 하다!
em.createQuery("select m.username from Team t join t.members m")
Java
복사
명시적 조인 VS 묵시적 조인
•
명시적 조인: join 키워드 직접 사용
◦
select m from Member m join m.team t
•
묵시적 조인: 경로 표현식에 의해 묵시적으로 SQL 조인 발생(내부 조인만 가능)
◦
select m.team from Member m
•
외부 조인을 하고 싶다면 명시적 조인을 사용해야 한다. 묵시적 조인은 내부 조인만 가능!
실무에서는 묵시적 JOIN이 발생하지 않도록 JPQL을 작성해야 한다.
•
묵시적 조인은 조인이 일어나는 상황을 한눈에 파악하기 어려움
◦
추후, 가공할 때의 있어서의 어려움(조인은 SQL 튜닝에 중요 포인트)
◦
유지보수의 어려움 등이 존재
패치 조인(fetch join)***
실무에서 굉장히 중요!!!!!
•
SQL 조인 종류X
•
JPQL에서 성능 최적화를 위해 제공하는 기능
•
연관된 엔티티나 컬렉션을 SQL 한 번에 함께 조회하는 기능
•
join fetch 명령어 사용페치 조인 ::= [ LEFT [OUTER] | INNER ] JOIN FETCH 조인경로
엔티티 패치 조인
•
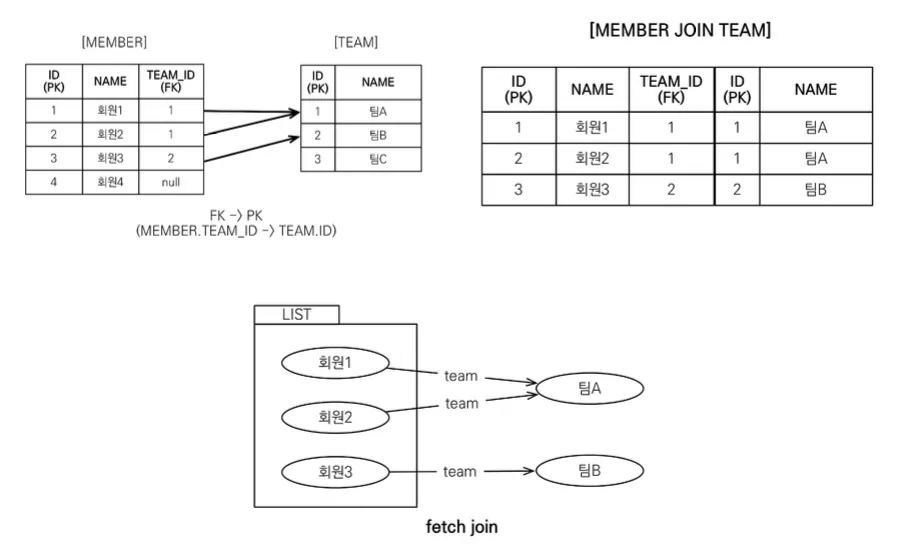
회원을 조회하면서 연관된 팀도 함께 조회(SQL 한 번에) SQL을 보면 회원 뿐만 아니라 팀(T.*)도 함께 SELECT
•
[JPQL] : select m from Member m join fetch m.team
•
[SQL] : SELECT M.*, T.* FROM MEMBER MINNER JOIN TEAM T ON M.TEAM_ID=T.ID
join fetch의 쿼리를 보면 전에 배웠던 즉시로딩과 같다!
→ 해당 쿼리를 작성해서 사용한다면, 지연 로딩이라도 무시하고 해당 쿼리를 보낸다.
예시
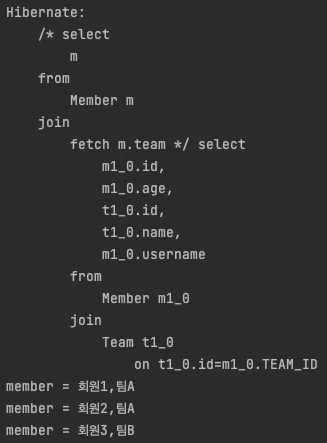
1. 문제점 (N+1 문제)
String query = "select m from Member m ";
List<Member> resultList = em.createQuery(query, Member.class)
.getResultList();
for (Member member : resultList) {
System.out.println("member = " + member.getUsername() + "," + member.getTeam().getName());
}
Java
복사
•
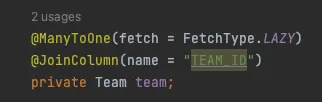
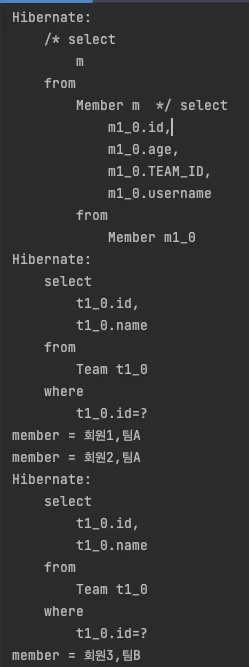
select m form Member m 이라는 JPQL을 작성했을 시에 Member 엔티티에 있는 team이 ManytoOne으로 작성되어 있고, fetchType이 LAZY로 설정되어 있다.
→ Team을 Proxy 엔티티로 가지고 온다.
•
그렇기 때문에, 첫 JPQL을 날렸을 때에는 Member 객체만 조회한 후
•
member.getTeam().getName() 을 호출했을 때 Team에 대한 쿼리를 날린다.
•
여기서 TeamA가 2명, TeamB가 1명이 있는데,
◦
TeamA가 한번 조회된 후 영속성 컨텍스트에 저장되기 때문에 쿼리 한번
▪
member = 회원1, 팀A ⇒ SQL 쿼리를 통해
▪
member = 회원2, 팀A ⇒ 영속성 컨텍스트를 통해
◦
TeamB는 영속성 컨텍스트에 없기 때문에 쿼리 한번이 나가
◦
총 2번의 쿼리가 더 실행된다.
이러한 문제가 만약 회원이 100명이라면?!?
•
최악의 경우에는 쿼리가 100번 나가게된다.
•
이를 N +1 문제라고 한다.
→ 회원을 가지고 오는 쿼리 1번, 팀을 조회하기 위해 보내는 쿼리 N번(최악의 경우)이기 때문에 N+1 이라고 한다.
2. 해결책
String query = "select m from Member m join fetch m.team ";
List<Member> resultList = em.createQuery(query, Member.class)
.getResultList();
for (Member member : resultList) {
System.out.println("member = " + member.getUsername() + "," + member.getTeam().getName());
}
Java
복사
•
join fetch 를 통해 한방 쿼리를 실행한다.
•
이 때는 이미 join을 통해 영속성 컨텍스트에 Team과 Member 모두가 저장되기 때문에, Proxy로 받아오지 않는다!
위의 N+1 문제를 해결하면서 성능을 아주 크게 끌어 올릴 수 있다!!
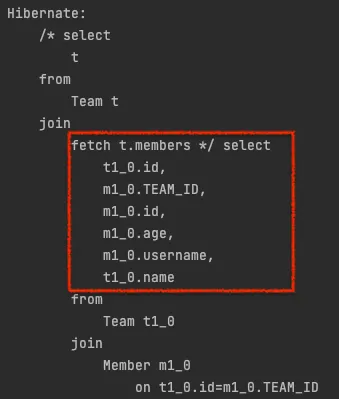
컬렉션 패치 조인
•
일대다 관계, 컬렉션 페치 조인
•
[JPQL] : select t from Team t join fetch t.members where t.name = ‘팀A'
•
[SQL] : SELECT T.*, M.*FROM TEAM T INNER JOIN MEMBER M ON T.ID=M.TEAM_ID WHERE T.NAME = '팀A
예시
String query = "select t from Team t join fetch t.members";
List<Team> resultList = em.createQuery(query, Team.class)
.getResultList();
for (Team team : resultList) {
System.out.println("team : " + team.getName() + "| members = " + team.getMembers().size());
}
Java
복사

하지만 나는 팀A, 팀B 딱 2줄만 나온다….
이유 : 하이버네이트6 부터는 DISTINCT 명령어를 사용하지 않아도 애플리케이션에서 중복 제거가 자동으로 적용됩니다.
•
해당 구문을 쿼리 했을 때 OneToMany 관계에서는 DB 로직에 의해 데이터가 뻥튀기 되서 옆에 결과 처럼 나오게 된다.
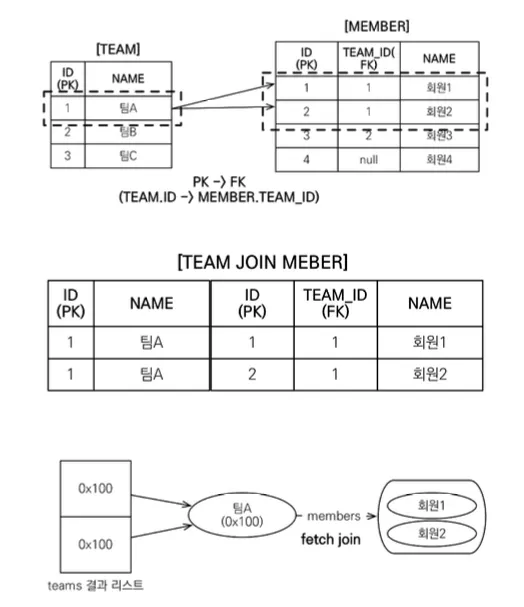
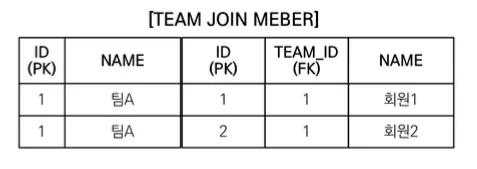
•
팀A는 한개지만, 멤버는 2명이기 때문에, DB 입장에서 Join을 하면 두 줄이 된다.
•
JPA입장에서 해당 부분을 처리하기에는 회원이 몇명인지 미리 알 수 없기 때문에 어떻게 할 수 없다.
→ 따라서 그냥 가지고 오게 된다.
•
하지만 영속성 컨텍스에 올라갈 때는, PK가 1번인 것 하나만 올라가게 된다.
패치 조인과 중복제거 DISTINCT
•
SQL의 DISTINCT는 중복된 결과를 제거하는 명령
•
JPQL의 DISTINCT 2가지 기능 제공
◦
1. SQL에 DISTINCT를 추가
◦
2. 애플리케이션에서 엔티티 중복 제거
예시
String query = "select DISTINCT t from Team t join fetch t.members";
List<Team> resultList = em.createQuery(query, Team.class)
.getResultList();
for (Team team : resultList) {
System.out.println("team : " + team.getName() + "| members = " + team.getMembers().size());
}
Java
복사
•
SQL에 DISTINCT를 추가하지만 데이터가 다르므로 SQL 결과에서 중복제거 실패
◦
SQL에서는 모든 항이 같아야 중복제거가 된다.
◦
하지만 해당 테이블에서는 Member의 ID와 NAME이 다르기 때문에 중복제거가 되지 않는다.
•
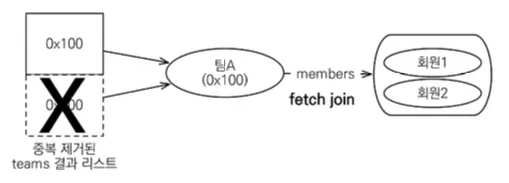
그렇기 때문에 JPA가 추가로 애플리케이션에서 중복 제거시도
◦
같은 식별자를 가진 Team 엔티티 제거
페치 조인과 일반 조인의 차이
•
일반 조인 실행시 연관된 엔티티를 함께 조회하지 않음
•
[JPQL] : select t from Team t join t.members m where t.name = ‘팀A'
•
[SQL] : SELECT T.*FROM TEAM T INNER JOIN MEMBER M ON T.ID=M.TEAM_ID WHERE T.NAME = '팀A'
•
JPQL은 결과를 반환할 때 연관관계 고려X
◦
단지 SELECT 절에 지정한 엔티티만 조회할 뿐
•
페치 조인을 사용할 때만 연관된 엔티티도 함께 조회(즉시 로딩)
•
페치 조인은 객체 그래프를 SQL 한번에 조회하는 개념
JOIN FETCH
JOIN
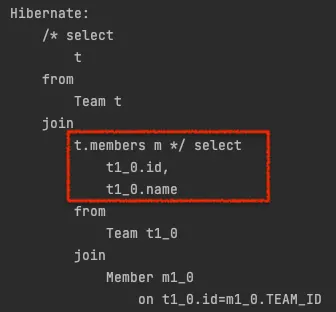
•
로딩 시점에 member에 대한 데이터가 영속성 컨텍스트에 저장되지 않는다.
•
즉, 이후에 사용될 때 쿼리를 통해 가지고오게 됨
→ Proxy랑 비슷하지만 컬렉션은 Proxy가 아니다.(동작은 Proxy와 동일)
Join Fetch 특징과 한계
•
페치 조인 대상에는 별칭을 줄 수 없다.
◦
하이버네이트는 가능, 가급적 사용X
•
둘 이상의 컬렉션은 페치 조인 할 수 없다.
•
컬렉션을 페치 조인하면 페이징 API(setFirstResult,setMaxResults)를 사용할 수 없다
◦
일대일, 다대일같은단일값연관필드들은페치조인해도페이징가능
◦
하이버네이트는 경고 로그를 남기고 메모리에서 페이징 (매우 위험)
•
연관된 엔티티들을 SQL 한 번으로 조회 - 성능 최적화
•
엔티티에 직접 적용하는 글로벌 로딩 전략보다 우선함
•
@OneToMany(fetch = FetchType.LAZY) //글로벌 로딩 전략
◦
실무에서 글로벌 로딩 전략은 모두 지연 로딩
◦
@BatchSize() 이용 시 각각 개별적으로 사용 가능
•
최적화가 필요한 곳은 페치 조인 적용
페이징에 있어서 N+1 문제가 발생하는데, 이를 해결하는 방법으로 크게 3가지 존재
1.
join fetch 사용
2.
컬렉션의 경우 페이징이 불가하기 때문에, batch size 이용
@BatchSize(size = 100)
@OneToMany(mappedBy = "team")
private List<Member> members = new ArrayList<>();
Java
복사
<property name="hibernate.default_batch_fetch_size" value="100"/> <!-- 적절히 1000 이하로-->
XML
복사
3.
DTO로 직접 쿼리 작성!!
정리
•
모든 것을 페치 조인으로 해결할 수 는 없음
•
페치 조인은 객체 그래프를 유지할 때 사용하면 효과적
•
여러 테이블을 조인해서 엔티티가 가진 모양이 아닌 전혀 다른결과를 내야 하면, 페치 조인 보다는 일반 조인을 사용하고 필요한 데이터들만 조회해서 DTO로 반환하는 것이 효과적
다형성 쿼리
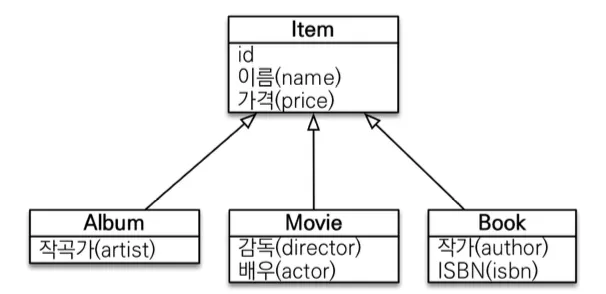
•
TYPE
◦
조회 대상을 특정 자식으로 한정
▪
예) Item 중에 Book, Movie를 조회해라
◦
[JPQL] : select i from Item i where type(i) IN (Book, Movie)
◦
[SQL] : select i from i where i.DTYPE in (‘B’, ‘M’)
•
TREAT(JPA 2.1)
◦
자바의 타입 캐스팅과 유사
◦
상속 구조에서 부모 타입을 특정 자식 타입으로 다룰 때 사용
◦
FROM, WHERE, SELECT(하이버네이트 지원) 사용
◦
예) 부모인 Item과 자식 Book이 있다.
▪
[JPQL] : select i from Item i where treat(i as Book).author = ‘kim’
▪
[SQL] : select i.* from Item i where i.DTYPE = ‘B’ and i.author = ‘kim’
엔티티 직접 사용
•
기본 키 값
◦
JPQL에서 엔티티를 직접 사용하면 SQL에서 해당 엔티티의 기본 키 값을 사용
◦
[JPQL]
▪
select count(m.id) from Member m ⇒ 엔티티의 아이디를 사용
▪
select count(m) from Member m ⇒ 엔티티를 직접 사용
◦
[SQL] (JPQL 둘다 같은 다음 SQL 실행)
▪
select count(m.id) as cnt from Member m
엔티티 전달 - 기본 키
String jpql = “select m from Member m where m = :member”;
List resultList = em.createQuery(jpql)
.setParameter("member", member)
.getResultList();
Java
복사
식별자를 직접 전달 - 기본 키
String jpql = “select m from Member m where m.id = :memberId”;
List resultList = em.createQuery(jpql)
.setParameter("memberId", memberId)
.getResultList();
Java
복사
실행될 쿼리
select m.* from Member m where m.id=?
SQL
복사
•
외래키 값
엔티티 전달 - 외래키
Team team = em.find(Team.class, 1L);
String qlString = “select m from Member m where m.team = :team”; List resultList = em.createQuery(qlString)
.setParameter("team", team)
.getResultList();
Java
복사
식별자를 직접 전달 - 외래키
String qlString = “select m from Member m where m.team.id = :teamId”; List resultList = em.createQuery(qlString)
.setParameter("teamId", teamId)
.getResultList();
Java
복사
실행될 쿼리
select m.* from Member m where m.team_id=?
SQL
복사
Named 쿼리
•
정적 쿼리
◦
미리 정의해서 이름을 부여해두고 사용하는 JPQL
◦
정적 쿼리
◦
어노테이션, XML에 정의
◦
애플리케이션 로딩 시점에 초기화 후 재사용
•
애플리케이션 로딩 시점에 쿼리를 검증
Named 쿼리 - 어노테이션
@Entity
@NamedQuery(
name = "Member.findByUsername",
query="select m from Member m where m.username = :username")
public class Member {...
}
Java
복사
List<Member> resultList =
em.createNamedQuery("Member.findByUsername", Member.class)
.setParameter("username", "회원1")
.getResultList();
Java
복사
Named 쿼리 - XML에 정의
•
[META-INF/persistence.xml]
<persistence-unit name="jpabook" >
<mapping-file>META-INF/ormMember.xml</mapping-file>
XML
복사
XML 정의가 항상 우선권을 가짐!
•
XML이 항상 우선권을 가진다.
•
애플리케이션 운영 환경에 따라 다른 XML을 배포할 수 있다.
•
[META-INF/ormMember.xml]
<?xml version="1.0" encoding="UTF-8"?>
<entity-mappings xmlns="http://xmlns.jcp.org/xml/ns/persistence/orm" version="2.1">
<named-query name="Member.findByUsername">
<query><![CDATA[
select m
from Member m
where m.username = :username
]]></query>
</named-query>
<named-query name="Member.count">
<query>select count(m) from Member m</query>
</named-query>
</entity-mappings>
XML
복사
벌크 연산
문제
•
재고가 10개 미만인 모든 상품의 가격을 10% 상승하려면?
•
JPA 변경 감지 기능으로 실행하려면 너무 많은 SQL 실행
1.
재고가 10개 미만인 상품을 리스트로 조회한다.
2.
상품 엔티티의 가격을 10% 증가한다.
3.
트렌젝션 커밋 시점에 변동 감지가 작동한다.
•
변경된 데이터가 100건이라면 100번의 UPDATE SQL 실행
해결
•
쿼리 한 번으로 여러 테이블 로우 변경(엔티티)
•
executeUpdate()의 결과는 영향받은 엔티티 수 반환
•
UPDATE, DELETE 지원
•
INSERT(insert into .. select, 하이버네이트 지원)
주의할 점!
•
벌크 연산은 영속성 컨텍스트를 무시하고 데이터베이스에 직접 쿼리 (commit, query, flush 시에 SQL쿼리가 나가게 된다.)
•
벌크 연산을 먼저 실행
•
벌크 연산 수행 후 영속성 컨텍스트 초기화
◦
벌크 연산시 쿼리가 나가게 되는데, 그렇게 되면 DB는 업데이트가 되도, 영속성 컨텍스트는 업데이트가 되지 않는다.
◦
그렇기 때문에, 영속성 컨텍스트를 초기화해준 후 새로 DB에서 데이터를 가지고 와야 한다.